Do You Know How Hash Table Works? (Ruby Examples)

What is hash table?
Hash table is a data structure that stores data in key-value pairs. It is also named as a dictionary or associative array. It stores data in a way that enables lookup and insertion in constant O(1) time. These properties of a hash make it one of the most useful data structures in a programmer’s toolbox.
The main question is where does this speed come from and how does it work?
WARNING: I need to mention that in ruby 2.4, Hash table is moved to open addressing model. Read more
(see links tat the end of the article). So in this article I will describe only how Hash-tables data
structure works, not how it is implemented in 2.4 and above.
The problem
Let’s imagine for a second that we store all entries in an array or a linked list. When we need to find something, we have to go through all of the elements to match one. This can take a very long time, depending on the number of elements.
Using a hash table, we can go directly to the cell with the value that we need to find just by computing the hash function for that key.
How does it work?
The hash table stores all values in the store (bins) groups, in a data structure similar to an array.
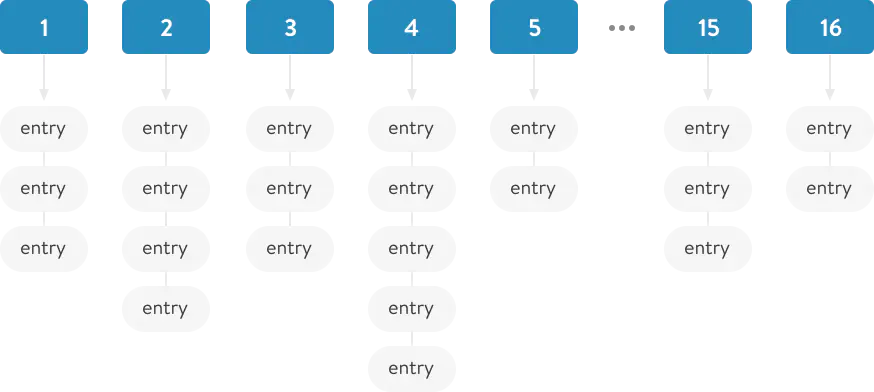
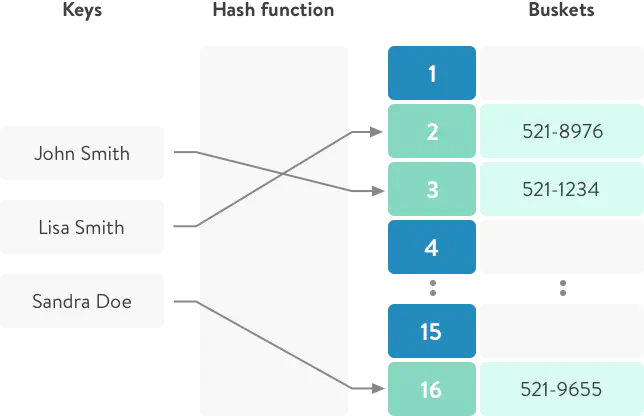
When adding a new key-value pair to the hash table, we need to calculate to which exact “storage” our pair will be inserted. We can do this using the .hash method (hash function).
The resulting value from the hash function is a pseudo-random number, i.e. it will always produce the same number for the same value.
In ruby - `hash` method belongs to the module `Kernel`. Thus, it exists for almost every object.
`hash` roughly speaking returns the equivalent of the link to the memory location where the current object is stored. But for strings, the calculation is relative to the value.
Having received a pseudo-random number - we must calculate the number of our “storage” where our key-value pair will lie.
'a'.hash % 16 =>9
a - key
16 - amount of storage
9 - the storage number
So when you add a key/value to a hash, it will always be bound to the same repository. And due to the fact that “hash” returns a pseudo-random number - our pairs will be evenly distributed between all storages.
The worst result is when the result of the function produces the same number. Since in such a result - all data will fall into one “storage” and that case will not be better than a simple array.
Wrapping up: How insertion works
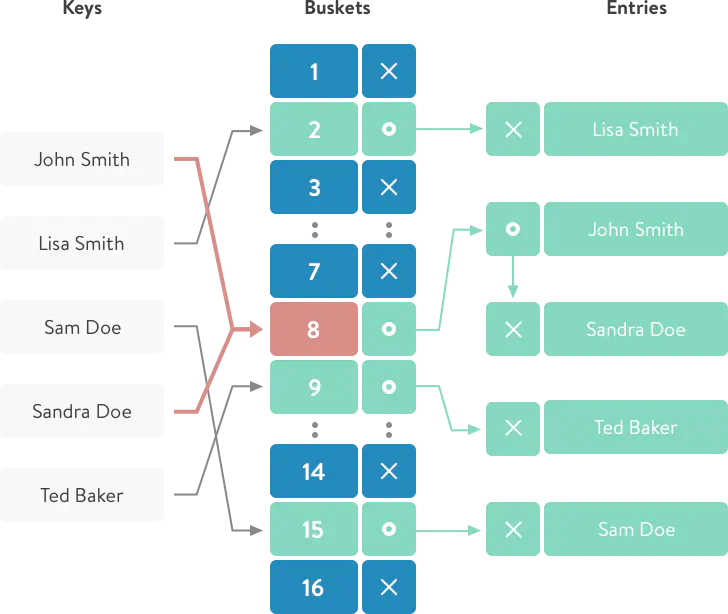
- The first thing ruby does is it takes the hash of the key using the internal hash function.
:c.hash #=> 2782
- After getting the random number (hash value), with the help of modulo operation (2782 % 16) we will get the storage number where to keep our key-value pair.
:d.hash % 16
- Add key-value to a linked list of the proper bin
Wrapping up: How search works
The first and second steps are the same:
- Determine “hash” function;
- Find “storage”;
- Then iterate through a small list and retrieve a hash element.
I just mentioned that we iterate through a small linked list.
In ruby, the average number of elements per bin is 5 (see more).
Collisions and Growth (Rehash)
With the increase in the number of records added, as a consequence, the density of elements will grow in each repository (in fact, that size of hash-table is only 16 storages).
If the density of the elements is large, for example 10_000 elements in one “storage”, while searching we will have to go through all the elements of this linked-list to find the corresponding record. And we’ll go back to O(n) time, which is pretty bad in this case.
To avoid such a situation, the tactic is applied: table rehash (table increases and re-compilation of cells).
What does it mean?
This means that hash-table size will be increased (up to the next number of - 16, 32, 64, 128, …) and for all current elements the position in the “storages” will be recalculated.
“Rehash” occurs when the number of all elements is greater than the maximum density multiplied by the current table size.
81 > 5 * 16 - rehash will be called when we add 81 elements to the table.
num_entries > ST_DEFAULT_MAX_DENSITY * table->num_bins
When the number of entries reaches the maximum possible value for current hash-table, the number of “storages” in that hash-table increases (it takes next size-number from 16, 32, 64, 128), and it re-calculates and corrects positions for all “entries” in that hash.
Here is a visual demonstration of how Ruby 2.3.4 behaves when you add a new element to the hash-table relative to the time.
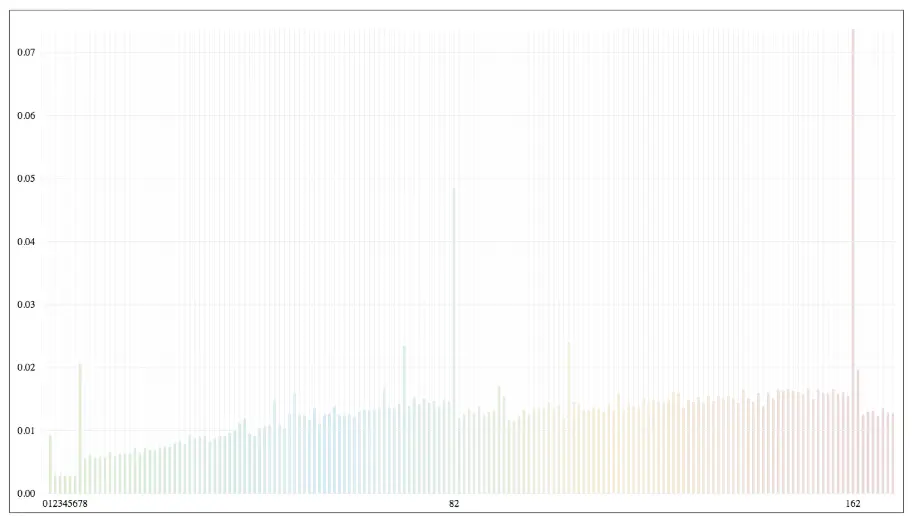
From the graph you can see that some insertion cause “Spikes” in the timeline. At this time - the “Rehash” of the hash-table occurs. After rehashing you can see that time to insert for next element is drops several ms.
In Ruby 2.0+, extra data structures for smaller hashes were removed. They use linear search for better performance. See more
Conclusion
Hash data structure is the common thing in programming. Implementation of the hash quite the same in Ruby development, Java, Python development. We just need to understand pros and cons of using it.
References & Links
Don't want to miss anything?
Subscribe and get stories like these right into your inbox.
Keep reading

IT Duel 2017 Implementation - The Game Engine
In the previous articles of the series we decided on the required playground functionality and prepared a runtime infrastructure for game bots and sandboxes.

IT Duel 2017 Implementation - DigitalOcean and Dokku Setup
In the first article, we covered the game rules and engine specs. Now, we’ll show how to use DigitalOcean and Dokku to let players write bots in various languages.

Metrics Collector: How to Optimize Your Business Insights
This article will introduce you the Ruby tool that we have built at Anadea to automate some repetitive processes.
Contact us
Let's explore how our expertise can help you achieve your goals! Drop us a line, and we'll get back to you shortly.